
Protocolli e architetture di instradamento/Algoritmi di instradamento
Gli algoritmi di instradamento presentati nel seguito assumono di operare su una rete basata sull'instradamento per indirizzo di rete. |
Un algoritmo di instradamento è un processo di tipo collaborativo responsabile di decidere, in ogni nodo intermedio, le direzioni che devono essere utilizzate per raggiungere le destinazioni:
- determina le destinazioni raggiungibili da ogni nodo:
- genera le informazioni sulla raggiungibilità delle reti locali: il router informa i router vicini che la rete locale esiste ed è raggiungibile attraverso di esso;
- riceve le informazioni sulla raggiungibilità delle reti remote: un router vicino informa il router che la rete remota esiste ed è raggiungibile attraverso di esso;
- propaga le informazioni sulla raggiungibilità delle reti remote: il router informa gli altri router vicini che la rete remota esiste ed è raggiungibile attraverso di esso;
- calcola i percorsi ottimali (next hop), in maniera cooperativa con gli altri nodi, secondo certi criteri:
- occorre stabilire una metrica: un percorso può essere il migliore in base a una metrica ma non in base a un'altra metrica;
- i criteri devono essere coerenti tra tutti i nodi nella rete per evitare cicli, buchi neri, ecc.;
- l'algoritmo deve operare in maniera automatica per evitare gli errori umani nella configurazione manuale e per favorire la scalabilità;
- memorizza delle informazioni locali nella tabella di instradamento di ogni nodo: un algoritmo di instradamento non necessita di conoscere l'intera topologia della rete, ma è solo interessato a costruire la tabella di instradamento corretta.
- Caratteristiche di un algoritmo di instradamento ideale
- semplice da implementare: meno bug, facile da capire, ecc.;
- leggero da eseguire: i router devono occupare meno risorse possibili per l'esecuzione dell'algoritmo poiché dispongono di CPU e memoria limitati;
- ottimale: i percorsi calcolati devono essere ottimali secondo le metriche scelte;
- stabile: deve passare a un altro percorso solo quando c'è un cambiamento di topologia o di costo per evitare il route flapping, cioè il cambiamento frequente delle rotte preferite con conseguente eccesso di periodi di transitorio;
- equo: non deve favorire alcun nodo o percorso particolare;
- robusto: deve essere capace di adattarsi automaticamente ai cambiamenti di topologia o di costo:
- rilevamento dei guasti: non deve affidarsi a componenti esterni per rilevare un guasto (ad es. un guasto non può essere rilevato a livello fisico se avviene al di là di un hub);
- autostabilizzazione: a fronte di variazioni nella rete deve convergere a una soluzione senza alcun intervento esterno (ad es. configurazione manuale esplicita);
- robustezza bizantina: deve riconoscere e isolare un nodo vicino che sta inviando delle informazioni fasulle, a causa di un guasto o di un attacco malevolo.
Internet non implementa la robustezza bizantina, ma si basa sulla fiducia → i guasti e i comportamenti malevoli richiedono l'intervento umano.
- Classificazione degli algoritmi di instradamento
- algoritmi non adattativi (statici): prendono le decisioni indipendentemente da come è fatta la rete:
- instradamento statico (o fixed directory routing)
- random walk
- flooding, flooding selettivo
- algoritmi adattativi (dinamici): apprendono informazioni sulla rete per prendere meglio le decisioni:
- instradamento centralizzato
- instradamento isolato: hot potato, backward learning
- instradamento distribuito: Distance Vector, Link State
- algoritmi gerarchici: permettono agli algoritmi di instradamento di scalare su infrastrutture ampie.
Metrica
[modifica | modifica sorgente]Una metrica è la misura di quanto buono è un percorso, ricavata dalla trasformazione di una grandezza fisica (ad es. distanza, velocità di trasmissione), o di una combinazione di esse, in forma numerica (costo), al fine di scegliere il percorso a costo inferiore come il percorso migliore.
Non esiste una metrica migliore per tutti i tipi di traffico: ad esempio la larghezza di banda è adatta per il traffico di trasferimento file, mentre il ritardo di trasmissione è adatto per il traffico in tempo reale. La scelta della metrica può essere determinata dal campo "Type of Service" (TOS) del pacchetto IP.
- Problemi
- (non-)ottimizzazione: il compito primario dei router è inoltrare il traffico degli utenti, non passare il tempo a calcolare percorsi → conviene prediligere soluzioni che, pur non essendo pienamente ottimizzate, non compromettono la funzionalità primaria della rete e non manifestano dei problemi percepibili dall'utente finale:
- complessità: più criteri vengono combinati, più l'algoritmo diventa complesso e richiede risorse computazionali in fase di esecuzione;
- stabilità: una metrica basata sulla banda disponibile sul link è troppo instabile, poiché dipende dal carico istantaneo di traffico che è molto variabile nel tempo, e può portare al route flapping;
- inconsistenza: le metriche adottate dai nodi nella rete devono essere coerenti (per ogni pacchetto) per evitare il rischio di cicli, ovvero il "rimbalzo" di un pacchetto tra due router che utilizzano metriche differenti in conflitto.
Transitori
[modifica | modifica sorgente]Gli algoritmi di instradamento moderni sono sempre "attivi": si scambiano dei messaggi di servizio continuamente per rilevare i guasti autonomamente. Tuttavia, non cambiano la tabella di instradamento a meno che non viene rilevato un cambiamento di stato:
- cambiamenti di topologia: guasto di un link, aggiunta di una nuova destinazione;
- cambiamenti di costo: ad esempio un link a 100 Mbps sale a 1 Gbps.
I cambiamenti di stato danno origine a fasi di transitorio: non è possibile aggiornare allo stesso tempo tutti i nodi di un sistema distribuito, poiché una variazione è propagata nella rete a velocità finita → durante il transitorio, le informazioni di stato nella rete possono non essere coerenti: alcuni nodi hanno già le informazioni nuove (ad es. il router che rileva il guasto), mentre altri hanno ancora le informazioni vecchie.
Non tutti i cambiamenti di stato hanno lo stesso impatto sul traffico dati:
- cambiamenti di stato positivi: l'effetto del transitorio è limitato perché la rete può solo funzionare temporaneamente in una condizione sub-ottimale:
- un percorso ottiene un costo migliore: alcuni pacchetti possono continuare a seguire il percorso vecchio ora divenuto meno conveniente;
- viene aggiunta una nuova destinazione: la destinazione può apparire irraggiungibile a causa di buchi neri lungo il percorso verso di essa;
- cambiamenti di stato negativi: l'effetto del transitorio si manifesta più gravemente all'utente perché interferisce anche con il traffico che non dovrebbe essere influenzato dal guasto:
- avviene il guasto di un link: non tutti i router hanno appreso che il percorso vecchio non è più disponibile → il pacchetto può cominciare a "rimbalzare" avanti e indietro saturando il link alternativo (routing loop);
- un percorso peggiora il proprio costo: non tutti i router hanno appreso che il percorso vecchio non è più conveniente → analogo al caso di guasto (routing loop).
In generale, due problemi comuni affliggono gli algoritmi di instradamento durante il transitorio: i buchi neri e i routing loop.
Buchi neri
[modifica | modifica sorgente]Si dice buco nero un router che, pur esistendo almeno un percorso attraverso cui potrebbe raggiungere una certa destinazione, non ne conosce (ancora) nessuno.
- Effetto
L'effetto sul traffico dati è limitato ai pacchetti diretti verso la destinazione interessata, che vengono scartati fino a quando il nodo non aggiorna la tabella di instradamento e acquisisce le informazioni su come raggiungerla. Il traffico diretto ad altre destinazioni non è assolutamente influenzato dal buco nero.
Routing loop
[modifica | modifica sorgente]Si dice routing loop un percorso ciclico dal punto di vista dell'instradamento: un router invia un pacchetto su un link ma, a causa di un'inconsistenza nelle tabelle di instradamento, il router all'altra estremità del link lo rispedisce indietro.
- Effetto
I pacchetti diretti verso la destinazione interessata cominciano a "rimbalzare" avanti e indietro (bouncing effect) → il link viene saturato → viene influenzato anche il traffico diretto ad altre destinazioni che passa per quel link.
Rotta di backup
[modifica | modifica sorgente]La rotta di backup è un concetto principalmente utilizzato nelle reti telefoniche basate su una organizzazione gerarchica: ogni centrale è collegata a una centrale di livello superiore con una rotta primaria, e a un'altra centrale di livello superiore con una rotta di backup → se avviene un guasto nella rotta primaria, la rotta di backup è pronta a entrare in funzione senza periodi di transitorio.
Una rete dati è invece basata su una topologia magliata, dove i router sono interconnessi in vario modo → è impossibile prevedere tutti i possibili guasti della rete per predisporre i percorsi di backup, ma quando avviene un guasto è preferibile un algoritmo di instradamento che calcoli automaticamente sul momento un percorso alternativo (anche se la fase di calcolo richiede un periodo di transitorio).
La rotta di backup nelle reti moderne può avere ancora delle applicazioni:
- un'azienda collegata a Internet tramite ADSL può mantenere la connettività quando la linea ADSL cade passando a una rotta di backup tramite tecnologia HiperLAN (senza fili);
- il backbone Internet è ormai in mano alle compagnie telefoniche, che l'hanno modellato secondo i criteri delle reti telefoniche → l'organizzazione è abbastanza gerarchica da consentire la predisposizione di rotte di backup.
Multipath routing
[modifica | modifica sorgente]Con l'instradamento per indirizzo di rete, tutti i pacchetti verso una destinazione passano per lo stesso percorso, anche se sono disponibili dei percorsi alternativi → sarebbe preferibile far passare una parte del traffico su un percorso alternativo, anche se di costo superiore, per non saturare il percorso scelto dall'algoritmo.
Il multipath routing, anche noto come "load sharing", è una funzione di traffic engineering che mira a distribuire il traffico verso la stessa destinazione su più percorsi (quando disponibili), consentendo più entry per ogni destinazione nella tabella di instradamento, per un uso più efficiente delle risorse di rete.
Multipath routing a costi differenziati
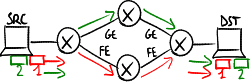
[modifica | modifica sorgente]Un percorso alternativo viene usato solo se ha un costo non troppo maggiore del costo del percorso primario a costo minimo:



Il traffico viene distribuito in modo inversamente proporzionale al costo delle rotte. Ad esempio in questo caso:

il router può decidere di mandare il pacchetto con il 66\% di probabilità lungo il percorso primario e con il 33% di probabilità lungo il percorso secondario.
- Problema
Dato un pacchetto, ogni router decide autonomamente su quale percorso inoltrarlo → decisioni incoerenti tra un router e l'altro possono far entrare il pacchetto in un routing loop, e siccome l'inoltro è di solito basato sulla sessione quel pacchetto non uscirà mai dal ciclo:

Multipath routing a costi equivalenti
[modifica | modifica sorgente]Un percorso alternativo viene usato solo se ha un costo esattamente uguale al costo del percorso primario ():


Il traffico viene partizionato equamente su entrambi i percorsi (50%).
- Problemi
Se il primo pacchetto segue il percorso lento e il secondo pacchetto segue il percorso veloce, i meccanismi del TCP possono causare il peggioramento delle prestazioni complessive:
- Problemi causati dal multipath routing a costi equivalenti.
-
 Problema di TCP reordering.
Problema di TCP reordering. -
 Riduzione della velocità di trasmissione.
Riduzione della velocità di trasmissione.


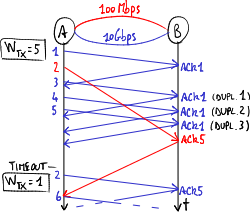
- problema di TCP reordering: i pacchetti possono arrivare fuori sequenza: il secondo pacchetto arriva alla destinazione prima del primo pacchetto → il processo di riordinamento dei numeri di sequenza impegna le risorse computazionali del ricevitore;
- riduzione della velocità di trasmissione: se il pacchetto di acknowledgment (ACK) del primo pacchetto arriva troppo in ritardo, la sorgente crede che il primo pacchetto sia andato perso → quando arrivano 3 ACK (cumulativi) duplicati e scade il timeout, entrano in azione i meccanismi a finestra di scorrimento del TCP:
- fast retransmit: la sorgente ritrasmette inutilmente il pacchetto → il pacchetto diventa duplicato;
- fast recovery: la sorgente crede che la rete sia congestionata → rallenta l'invio di pacchetti limitando la finestra di trasmissione: imposta il valore di soglia alla metà del valore corrente della finestra di congestione, e fa ripartire la finestra di congestione dal valore 1 (cioè viene mandato un solo pacchetto per volta e se ne attende l'ACK prima di mandare il pacchetto successivo).
Criteri
[modifica | modifica sorgente]Le implementazioni reali del multipath routing suddividono il traffico in modo che il traffico verso una stessa destinazione segua lo stesso percorso:
- in base al flusso: ogni sessione di livello trasporto è identificata dalla quintupla:
<indirizzo IP sorgente><indirizzo IP di destinazione><tipo di protocollo di livello trasporto>(ad es. TCP)<porta sorgente><porta di destinazione>
e il router memorizza una tabella che mappa gli identificativi di sessione con le porte di uscita:
- l'estrazione dal pacchetto dei campi che formano l'ID di sessione è onerosa, a causa della varietà di formati di pacchetto supportati (VLAN, MPLS...);
- le informazioni sulle porte di livello trasporto non sono disponibili in caso di pacchetti IP frammentati;
- la ricerca della quintupla nella tabella degli ID di sessione è onerosa;
- spesso la chiusura delle connessioni TCP non è "graceful leaving", cioè non vengono inviati i pacchetti FIN e ACK → le entry nella tabella degli ID di sessione non vengono cancellate → occorre un thread che ogni tanto effettui la pulizia delle entry vecchie guardandone i timestamp;
- in base al pacchetto: il router invia i pacchetti con indirizzo IP (di destinazione o sorgente o entrambi) pari su un percorso, e con indirizzo IP dispari sull'altro percorso → l'operazione di hashing è molto rapida.
- Problema
Il traffico verso una stessa destinazione non può usare entrambi i percorsi allo stesso tempo → ci sono dei problemi in caso di traffico molto grande verso una certa destinazione (ad es. un backup notturno tra due server).
Algoritmi non adattativi
[modifica | modifica sorgente]Instradamento statico
[modifica | modifica sorgente]L'amministratore della rete configura manualmente su ogni router la tabella di instradamento.
- Svantaggio
Se avviene un cambiamento nella rete, bisogna aggiornare manualmente le tabelle di instradamento.
- Applicazione
L'instradamento statico è utilizzato principalmente sui router ai margini della rete:

- ai router edge non è consentito propagare le informazioni di instradamento verso il backbone: il router core blocca tutti gli annunci in arrivo dalla periferia, altrimenti un utente potrebbe annunciare una rete con lo stesso indirizzo di una rete esistente (ad es. google.com) e dirottare verso di lui una parte del traffico diretto a quella rete.
Dato che gli utenti non possono annunciare le proprie reti, come fanno a essere raggiungibili dall'esterno? L'ISP, che sa quali indirizzi usano le reti che ha venduto agli utenti, deve configurare il router core in modo che annunci quelle reti agli altri router anche se esse non sono localmente connesse; - ai router edge non è consentito ricevere le informazioni di instradamento dal backbone: un router edge è tipicamente connesso con un singolo link a un router core → una rotta predefinita globale è sufficiente per raggiungere l'intera Internet.
Random walk
[modifica | modifica sorgente]Quando arriva un pacchetto, il router sceglie una porta a caso (tranne quella da cui è stato ricevuto) e lo manda in uscita su quella porta.
- Applicazioni
È utile quando la probabilità che il pacchetto raggiunga la destinazione è elevata:
- reti peer-to-peer (P2P): per la ricerca dei contenuti;
- reti di sensori: l'invio di messaggi deve essere un'operazione a basso consumo.
Flooding
[modifica | modifica sorgente]Quando arriva un pacchetto, il router lo manda in uscita su tutte le porte (tranne quella da cui è stato ricevuto).
I pacchetti possono avere un campo "numero di hop" per limitare il flooding a una porzione della rete.
- Applicazioni
- applicazioni militari: in caso di attacco la rete potrebbe essere danneggiata → è fondamentale che il pacchetto arrivi a destinazione, anche a costo di avere un'enorme quantità di traffico duplicato;
- algoritmo Link State: ogni router quando riceve la mappa della rete da un vicino deve propagarla agli altri vicini:
 A4. L'algoritmo Link State#Algoritmo di flooding.
A4. L'algoritmo Link State#Algoritmo di flooding.
Flooding selettivo
[modifica | modifica sorgente]Quando arriva un pacchetto, il router prima controlla se lo ha già ricevuto e mandato in flooding in passato:
- pacchetto vecchio: lo scarta;
- pacchetto nuovo: lo memorizza e lo manda in uscita su tutte le porte (tranne quella da cui è stato ricevuto).
Ogni pacchetto è riconosciuto tramite l'identificativo del mittente (ad es. l'indirizzo IP sorgente) e il numero di sequenza:
- se il mittente si disconnette dalla rete o si spegne, quando si riconnette il numero di sequenza ricomincia da capo → il router vede tutti i pacchetti ricevuti come pacchetti vecchi;
- i numeri di sequenza sono codificati su un numero limitato di bit → lo spazio dei numeri di sequenza deve essere scelto in modo da minimizzare l'errato riconoscimento di pacchetti nuovi come pacchetti vecchi.
Spazi dei numeri di sequenza
[modifica | modifica sorgente]- Spazio lineare
Può essere tollerabile se il selective flooding è usato per pochi messaggi di controllo:
- quando il numero di sequenza raggiunge il valore massimo possibile, si verifica un errore di overflow;
- pacchetto vecchio: il numero di sequenza è minore di quello corrente;
- pacchetto nuovo: il numero di sequenza è maggiore di quello corrente.
- Spazio circolare
Risolve il problema dell'esaurimento dello spazio dei numeri di sequenza, ma fallisce se arriva un pacchetto con numero di sequenza troppo lontano da quello corrente:
- quando il numero di sequenza raggiunge il valore massimo possibile, il numero di sequenza ricomincia dal valore minimo;
- pacchetto vecchio: il numero di sequenza è nella metà precedente a quello corrente;
- pacchetto nuovo: il numero di sequenza è nella metà successiva a quello corrente.
- Spazio lecca-lecca
La prima metà dello spazio è lineare, la seconda metà è circolare.
Algoritmi adattativi
[modifica | modifica sorgente]Instradamento centralizzato
[modifica | modifica sorgente]Tutti i router sono collegati a un nucleo di controllo centralizzato chiamato Routing Control Center (RCC): ogni router dice al RCC quali sono i propri vicini, e il RCC usa queste informazioni per creare la mappa della rete, calcolare le tabelle di instradamento e comunicarle a tutti i router.
- Vantaggi
- prestazioni: i router non devono avere un'elevata capacità di calcolo, concentrata tutta su un singolo apparato;
- debug: l'amministratore di rete può ottenere la mappa dell'intera rete da un singolo apparato per verificarne la correttezza;
- manutenzione: l'intelligenza è concentrata nel centro di controllo → per aggiornare l'algoritmo basta aggiornare il centro di controllo.
- Svantaggi
- tolleranza ai guasti: il centro di controllo è un singolo punto di guasto → un malfunzionamento del centro di controllo impatta su tutta la rete;
- scalabilità: più router compongono la rete, più il lavoro per il centro di controllo aumenta → non è adatto per reti ampie come Internet.
- Applicazione
Principi simili sono utilizzati nelle reti telefoniche.
Instradamento isolato
[modifica | modifica sorgente]Non c'è alcun centro di controllo, ma tutti i nodi sono paritetici: ogni nodo decide i percorsi autonomamente senza scambiare informazioni con gli altri router.
- Vantaggi e svantaggi
Sono praticamente gli opposti di quelli dell'instradamento centralizzato.
Backward learning
[modifica | modifica sorgente]Ogni nodo apprende informazioni sulla rete in base all'indirizzo sorgente dei pacchetti: ![]() Progetto di reti locali/A3. Repeater e bridge#Trasparent bridge.
Progetto di reti locali/A3. Repeater e bridge#Trasparent bridge.
- funziona bene solo con nodi "loquaci";
- non è facile capire di dover passare a un percorso alternativo quando il percorso migliore diventa non più disponibile;
- non è facile rilevare le destinazioni diventate irraggiungibili → è richiesto un timer speciale per eliminare le entry vecchie.
Instradamento distribuito
[modifica | modifica sorgente]L'instradamento distribuito utilizza un modello "paritetico": prende i vantaggi dell'instradamento centralizzato e quelli dell'instradamento isolato:
- instradamento centralizzato: i router partecipano nello scambio di informazioni riguardanti la connettività;
- instradamento isolato: i router sono equivalenti e non c'è un router "migliore".
- Applicazioni
I moderni protocolli di instradamento utilizzano due principali algoritmi di instradamento distribuito:
- Distance Vector: ogni nodo dice a tutti i vicini che cosa sa della rete;
- Link State: ogni nodo dice a tutta la rete che cosa sa dei propri vicini.
Confronto
[modifica | modifica sorgente]- Vicini
- LS: ha bisogno del protocollo di "hello";
- DV: conosce i suoi vicini attraverso il DV stesso.
- Tabella di instradamento
DV e LS creano la stessa tabella di instradamento, solo calcolata in modi differenti e con differente durata (e comportamento) del transitorio:
- LS: i router cooperano per mantenere la mappa della rete aggiornata, quindi ognuno di essi calcola il proprio albero ricoprente: ogni router conosce la topologia della rete, e conosce il percorso preciso per raggiungere una destinazione;
- DV: i router cooperano per calcolare la tabella di instradamento: ogni router conosce solo i suoi vicini, e si fida di loro per determinare il percorso verso la destinazione.
- Semplicità
- DV: singolo algoritmo facile da implementare;
- LS: incorpora molti componenti diversi.
- Debug
Migliore in LS: ogni nodo ha la mappa della rete.
- Consumo di memoria (in ogni nodo)
Possono essere considerati equivalenti:
- LS: ognuno degli LS ha adiacenze (Dijkstra: );
- DV: ognuno degli DV ha destinazioni (Bellman-Ford: ).




- Traffico
Migliore in LS: i pacchetti Neighbor Greeting sono molto più piccoli dei DV.
- Convergenza
Migliore in LS: il rilevamento dei guasti è più rapido perché è basato sui pacchetti Neighbor Greeting inviati ad alta frequenza.