
Tecnologie e servizi di rete/Migrazione a IPv6
Introduzione
[modifica | modifica sorgente]Durante la fase di transizione, gli host devono cominciare gradualmente a poter raggiungere le destinazioni IPv6 continuando a essere in grado di raggiungere le destinazioni IPv4. La migrazione di tutti gli apparati di rete è una condizione necessaria ma non sufficiente: l'utente deve farli lavorare insieme creando un nuovo piano di indirizzamento per l'intera rete.
Migrazione degli host
[modifica | modifica sorgente]Migrazione delle applicazioni
[modifica | modifica sorgente]L'introduzione del supporto a IPv6 nelle applicazioni comporta la necessità di modificare il codice sorgente:
- server: il processo in esecuzione su un server deve aprire due thread, uno in ascolto sul socket IPv4 e l'altro in ascolto sul socket IPv6, al fine di poter servire richieste sia IPv4 sia IPv6;
- client: le applicazioni come i browser Web devono essere in grado di stampare in output e ricevere in input gli indirizzi nel nuovo formato.
Migrazione dei sistemi operativi
[modifica | modifica sorgente]-
 Dual stack senza dual layer.
Dual stack senza dual layer. -
 Dual stack con dual layer.
Dual stack con dual layer.


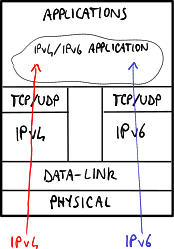
Le applicazioni giacciono per lo più sulle librerie del sistema operativo, che possono introdurre il supporto a IPv6 adottando l'approccio dual stack:
- senza dual layer: il sistema operativo elabora indipendentemente gli indirizzi IPv4 e IPv6 → il software deve essere in grado di gestire indirizzi sia IPv4 sia IPv6;
- con dual layer: il sistema operativo è in grado di convertire un indirizzo IPv4 in un indirizzo IPv6 IPv4-mapped → il software può limitarsi a supportare gli indirizzi IPv6 senza curarsi degli indirizzi IPv4.
La variante con dual layer è la più utilizzata perché sposta la complessità al core del sistema operativo.
Migrazione degli apparati di rete
[modifica | modifica sorgente]Migrazione degli switch
[modifica | modifica sorgente]Anche se in teoria gli switch non dovrebbero essere influenzati assolutamente dai cambiamenti a livello 3 perché essi lavorano fino al livello 2, ci potrebbero essere alcuni problemi con le funzioni aggiuntive: per esempio l'IGMP snooping, una funzionalità utilizzata per filtrare i pacchetti multicast in arrivo, ha bisogno di guardare all'interno del pacchetto → poiché cambiano il formato e i campi del pacchetto lo switch non riesce a riconoscere i pacchetti IPv6 multicast e li scarta.
Migrazione dei router
[modifica | modifica sorgente]| Per approfondire, vedi Protocolli e architetture di instradamento/Instradamento IPv6. |
Oggi i router sono per lo più pronti per IPv6, anche se le prestazioni in IPv6 sono ancora peggiori rispetto a quelle in IPv4 a causa della mancanza di esperienza e della più bassa domanda di traffico.
Tipicamente i router che supportano IPv6 adottano l'approccio dual stack di tipo "navi nella notte": IPv4 e IPv6 sono supportati da due pile indipendenti per il livello trasporto → questo richiede la completa duplicazione di tutti i componenti: protocolli di instradamento, tabelle di instradamento, liste di accesso, ecc.
Tabelle di instradamento
[modifica | modifica sorgente]L'instradamento in IPv6 è effettuato nello stesso modo di IPv4 ma richiede due tabelle di instradamento distinte, una per le rotte IPv4 e l'altra per le rotte IPv6. Le tabelle di instradamento IPv6 possono memorizzare diversi tipi di entry, tra cui:
- entry indirette (codici O/S): specificano gli indirizzi, tipicamente link local, delle interfacce dei router next hop ai quali inviare i pacchetti indirizzati verso link remoti;
- entry dirette: specificano le interfacce del router stesso attraverso le quali inviare i pacchetti indirizzati verso i link locali:
- reti connesse (codice C): specificano i prefissi dei link locali;
- indirizzi di interfaccia (codice L): specificano gli interface identifier nei link locali.
Protocolli di instradamento
[modifica | modifica sorgente]I protocolli di instradamento che supportano IPv6 possono adottare due approcci:
- instradamento integrato (ad es. BGP): il protocollo consente di scambiare informazioni di instradamento sia IPv4 sia IPv6 allo stesso tempo → gli indirizzi IPv4 e IPv6 appartenenti alla stessa destinazione possono essere trasportati tramite un singolo messaggio → efficienza maggiore;
- navi nella notte (ad es. RIP, OSPF): il protocollo consente di scambiare informazioni di instradamento solo IPv6 → data una destinazione, deve essere scambiato un messaggio per il suo indirizzo IPv4 e un altro messaggio per il suo indirizzo IPv6, e i messaggi sono completamente indipendenti tra loro → flessibilità maggiore: si possono usare due protocolli diversi, uno per le informazioni di instradamento IPv4 e un altro per le informazioni di instradamento IPv6.
Migrazione dei DNS
[modifica | modifica sorgente]I DNS che supportano IPv6 possono mappare due indirizzi IP allo stesso alias: un indirizzo IPv4 e uno IPv6 → una destinazione pubblica può essere raggiungibile tramite IPv4 oppure tramite IPv6.
I DNS che supportano IPv6 possono restituire gli indirizzi IPv6 non solo tramite IPv6, ma anche tramite IPv4: i messaggi DNS appartengono infatti al livello applicazione, così non importa il livello trasporto utilizzato per inoltrare le query e le risposte DNS. Le query DNSv6 vengono effettuate con il comando seguente: set q=aaaa.
Una società può decidere di offrire l'accesso al proprio sito Web pubblico anche tramite IPv6. Tuttavia, attualmente la maggior parte del traffico è tramite IPv4, così generalmente il servizio per il traffico IPv4 è più affidabile in termini di prestazioni e tolleranza ai guasti rispetto a quello per il traffico IPv6. Perciò la società, soprattutto se basa il business sul suo sito Web, non vuole che l'utente che si connette tramite IPv6 decida di passare a un altro sito Web concorrente a causa di problemi prestazionali. Una soluzione possibile è effettuare alcuni accertamenti preliminari per testare le prestazioni della connettività tra l'utente e il server della società, e implementare un meccanismo aggiuntivo nei DNS: essi dovrebbero essere capaci di guardare l'indirizzo sorgente della query DNS, e restituire solamente l'indirizzo IPv4 se non è stato effettuato alcun accertamento per la connettività, oppure entrambi gli indirizzi IPv4 e IPv6 se le prestazioni sono sufficientemente buone.
Soluzioni di tunneling
[modifica | modifica sorgente]La rete non sarà compatibile con IPv6 dal giorno zero → il traffico IPv6 potrebbe dover attraversare delle porzioni di rete solo IPv4. Le soluzioni di tunneling orientate alla rete permettono la connettività tra le reti IPv6 anche se esse sono connesse attraverso un'infrastruttura solo IPv4, e consistono nell'incapsulamento del pacchetto IPv6 all'interno di un'intestazione IPv4 solo per il trasporto lungo il tunnel:

La dimensione del pacchetto nel tunnel, compresa l'intestazione IPv4 lunga 20 byte, non deve superare la dimensione massima dei pacchetti IPv4 → sono possibili due soluzioni:
- frammentazione: i router dovrebbero frammentare il pacchetto IPv4 prima di mandarlo nel tunnel → la frammentazione è deprecata per motivi prestazionali;
- pacchetti IPv6 più piccoli: gli host dovrebbero generare dei pacchetti IPv6 con una dimensione della MTU più piccola per tenere conto della dimensione supplementare dovuta all'inserimento dell'intestazione IPv4 → i router possono specificare la dimensione della MTU consentita attraverso i messaggi ICMPv6 "Router Advertisement".
Soluzioni di tunneling orientate agli host
[modifica | modifica sorgente]Le soluzioni di tunneling orientate agli host sono più plug-and-play per gli host, ma non sono soluzioni professionali e non risolvono il problema della scarsità di indirizzi IPv4 perché ogni host ha ancora bisogno di avere un indirizzo IPv4. Le soluzioni di questo tipo sono:
- uso degli indirizzi IPv6 IPv4-compatible, con terminazione del tunnel sull'host o sul router;
- 6over4;
- ISATAP.
Uso degli indirizzi IPv6 IPv4-compatible
[modifica | modifica sorgente]Si basano sul fatto che gli host dual-stack, quando è necessario contattare una destinazione IPv4, inviino pacchetti IPv6 ad un indirizzo IPv6 IPv4-compatible, cioè costruito con i primi 96 bit alti a zero e con i restanti 32 coincidenti con quelli dell'indirizzo IPv4 di destinazione. Tale pacchetto IPv6 viene poi incapsulato in un pacchetto IPv4, la cui destinazione è diversa a seconda che si voglia terminare il tunnel sull'host di destinazione o su un router dual-stack, in particolare:
- terminazione end-to-end: la pseudo-interfaccia sull'host dual-stack effettua l'incapsulamento in un pacchetto IPv4 destinato all'host che si vuole contattare;
- terminazione sul router dual-stack: la pseudo-interfaccia sull'host manda i pacchetti destinati ad un host all'indirizzo IPv4 del router dual-stack, quindi:
- si genera un indirizzo IPv6 IPv4-compatible per la destinazione, come prima;
- si incapsula il pacchetto IPv6 in uno IPv4 destinato al router dual-stack;
- il router dual-stack decapsula il pacchetto e invia all'host di destinazione.
6over4
[modifica | modifica sorgente]L'idea è quella di emulare, attraverso IPv4, una rete locale che ha supporto al multicast. In pratica, come per connettere due host IPv6 attraverso la rete Ethernet sottostante si usa la neighbor discovery, appoggiandosi al fatto che Ethernet ha dei meccanismi per il broadcast, in questa soluzione si ragiona come se fosse IPv4 il protocollo di livello inferiore e si modifica la neighbor discovery per trovare indirizzi IPv4 al posto di indirizzi MAC. Questo discorso può essere generalizzato al caso in cui si vogliono connettere non dei singoli host, ma nuvole di reti IPv6 attraverso router dual-stack che comunicano in una rete IPv4. In questo caso, oltre alla neighbor discovery, si può utilizzare una versione modificata della router discovery, in modo da inviare una router solicitation per scoprire gli indirizzi IPv4 dei router connessi alla rete IPv4 dell'host che consentono di raggiungere varie reti IPv6; infatti dalla router advertisement l'host può avere informazioni sulle reti IPv6 che si possono raggiungere da quel router.
Il problema di questa soluzione è l'uso dell'IPv4 multicast, che di solito è disabilitato nelle reti che coinvolgono provider diversi. Questa soluzione è utilizzabile quando si ha una rete tutta sotto il proprio controllo: per questo motivo essa non è utilizzabile per migrare la rete globale da IPv4 a IPv6.
Neighbor discovery di 6over4
[modifica | modifica sorgente]Su proposta dell'RFC, gli indirizzi IPv6 sono mappati sugli indirizzi IPv4: in pratica l'indirizzo IPv4 viene usato come interface identifier dell'indirizzo IPv6 della destinazione. Ciò renderebbe inutile il meccanismo illustrato finora, perché l'host potrebbe effettuare il tunneling direttamente, senza bisogno della neighbor discorvery per conoscere l'indirizzo IPv4. Ciò ovviamente non è valido quando l'indirizzo IPv6 non è costruito a partire da quello IPv4, quindi per contattare un router è comunque necessario un meccanismo più generale.
Supponendo, quindi, di conoscere soltanto un indirizzo IPv6, si invia la neighbor discovery al solicited node multicast address (ad esempio se l'indirizzo IPv6 è fe80::101:101 allora si manda a ff02::1:ff01:101) su una rete IPv4 6over4 multicast all'inidirizzo 239.192.x.y, costruito con gli ultimi 16 bit dell'indirizzo IPv6 (quindi nell'esempio precedente sarà 239.192.1.1).
ISATAP
[modifica | modifica sorgente]L'idea è simile a quella del 6over4, cioè usare la rete IPv4 come link fisico per raggiungere le destinazioni IPv6, ma si vuole superare la limitazione di richiedere il supporto al multicast. In assenza dei meccanismi di neighbor discovery, l'indirizzo IPv4 delle destinazioni che usano ISATAP viene incorporato nell'indirizzo IPv6, più precisamente nell'interface identifier, che ha la forma 0000:5efe:x:y, in cui x e y sono i 32 bit dell'indirizzo IPv4.
Come si intuisce, questa soluzione non affronta il problema per cui si è introdotto IPv6, cioè la scarsità di indirizzi IPv4. Questa soluzione è però più utile nello scenario di un link IPv4 che connette non host, ma router cha hanno al confine delle nuvole IPv6. In questo caso un host all'interno della rete IPv4 che voglia comunicare in IPv6 con un host appartenente ad una nuvola dovrà essere dotato di una Potential Router List (PRL). I problemi che a questo punto si pongono sono:
- Come viene acquisita la PRL?
- Ci sono due diverse soluzioni: la prima, che è proprietaria, si basa sull'uso del DHCP; la seconda, che è standard, si basa sull'uso del DNS. Nella seconda si usa una query DNS per un nome particolare dal formato
isatap.dominio.it, che fornirà la PRL dei router IPv6 collegati alla rete IPv4 del dominio specificato nella query.
- A quale router devono essere inviati i pacchetti per la destinazione IPv6?
- Si usa una router discovery unicast ad ognuno dei router della PRL, in modo da farsi rispondere con una router advertisement. Si ricordi, infatti, che nella router advertisement i router possono anche annunciare la lista delle reti IPv6 che si possono raggiungere tramite essi (vedi il flag
L=0nella Prefix Information Option della ICMP Router Advertisement).
Soluzioni di tunneling orientate alla rete
[modifica | modifica sorgente]Tipicamente le soluzioni di tunneling orientate alla rete richiedono la configurazione manuale, e l'incapsulamento può essere basato su IPv6 in IPv4 (protocol type = 41), GRE, IPsec, ecc.
6to4
[modifica | modifica sorgente]Il più grande passo in avanti rispetto alle soluzioni precedenti viene dalla considerazione che nel nuovo scenario c'è una intera rete IPv6 che ha bisogno di un indirizzo IPv4 per uscire dalla nuvola IPv6, non più un singolo host. Il mapping tra i due indirizzi viene quindi effettuato nel prefisso IPv6, non nell'interface identifier: si assegna a tutte le reti IPv6 un prefisso speciale che includa l'indirizzo IPv4 assegnato all'interfaccia del router dual-stack che si affaccia sulla nuvola. Il prefisso 2002::/16 identifica delle stazioni IPv6 che stanno usando 6to4: nei successivi 32 bit si pone l'indirizzo IPv4 e altri 16 rimangono disponibili per rappresentare più subnet diverse, mentre l'interface identifier si ottiene come negli altri casi di uso di IPv6.
In questa soluzione esiste anche un router che ha un ruolo particolare, il 6to4 Relay, che deve essere il default gateway dei router 6to4, in modo da inoltrare alla IPv6 globale i pacchetti che non hanno il formato dei 6to4 appena visto. Questo router ha indirizzo 192.88.99.1, che è un indirizzo anycast: è stato usato da chi ha pensato il 6to4 perché si è pensato allo scenario in cui nella stessa rete ci siano più 6to4 Relay, da cui nascerebbe il problema di dover usare indirizzi diversi. In questo modo invece, poiché l'indirizzo anycast è processato in maniera diversa dai protocolli di routing, si può usare lo stesso indirizzo e fornire anche del load balancing.
Esempio pratico
[modifica | modifica sorgente]Ipotizziamo che ci siano due nuvole IPv6 collegate ad una nuvola IPv4, e che le interfacce dei router dual-stack abbiano, per le interfacce collegate alle nuvole IPv6, gli indirizzi 192.1.2.3 per la rete A e 9.254.2.252 per la rete B. Supponiamo inoltre che un host a appartenente alla rete A voglia inviare un pacchetto all'host b appartenente alla rete B. Dalla configurazione delineata e da quanto detto si ricava che gli host presenti nella rete A avranno un indirizzo del tipo 2002:c001:02:03/48 e quelli presenti nella rete B 2002:09fe:02fc::/48. Il pacchetto IPv6 da a a b sarà incapsulato in un pacchetto IPv4 che ha come indirizzo di destinazione 9.254.2.252, ricavato dal prefisso dell'indirizzo IPv6 di destinazione: quando il pacchetto arriverà a quel router, esso sarà decapsulato e inoltrato secondo il piano di indirizzamento IPv6 della nuvola contenente la rete B.
Teredo
[modifica | modifica sorgente]È molto simile al 6to4, tranne per il fatto che l'incapsulamento è effettuato dentro un segmento UDP contenuto in una pacchetto IPv4, al posto di essere semplicemente incapsulato in IPv4. Questo si fa per superare un limite del 6to4, cioè il passaggio attraverso i NAT: poiché nel 6to4 non è presente un segmento di livello 2 dentro il pacchetto IPv4 incapsulante, il NAT non può funzionare.
Tunnel broker
[modifica | modifica sorgente]Il problema della soluzione 6to4 è che non è sufficientemente generica: si è vincolati all'uso degli indirizzi 2002::/16 e non si possono usare i comuni global unicast. Nella soluzione con tunnel broker, visto che non è più possibile dedurre dal prefisso IPv6 quale sia l'endpoint a cui mandare il pacchetto, si utilizza un server che, dato un generico indirizzo IPv6, fornisce l'indirizzo del tunnel endpoint da contattare. I router che implementano il tunnel broker sono chiamati tunnel server, mentre i server che forniscono il mapping si chiamano tunnel broker server. I tunnel sono realizzati come in 6to4, quindi IPv6 dentro IPv4: se ci fosse il problema di attraversare un NAT si potrebbe anche pensare di usare l'approccio di Teredo, incapsulando dentro UDP, quindi dentro IPv4.
Il tunnel broker server deve essere configurato: viene usato il Tunnel Information Control (TIC) per inoltrare le informazioni sulle reti raggiungibili da un determinato tunnel server, dal tunnel server che si sta configurando al tunnel broker server. Il Tunnel Setup Protocol (TSP) viene invece usato per chiedere le informazioni al tunnel broker server. Anche in questo caso si può avere un default gateway per la rete IPv6 globale. Ricapitolando, un router con questa configurazione, quando arriva un pacchetto, può:
- inoltrarlo direttamente se fa match con una entry nella tabella di instradamento (situazione classica);
- chiedere al tunnel broker server per vedere se si tratta di un indirizzo per cui serve il tunneling;
- mandarlo su un default gateway per la IPv6 globale se la risposta del tunnel broker server è negativa.
Problemi
[modifica | modifica sorgente]- È una soluzione centralizzata e per questo il tunnel broker server è un single point of failure.
- Complica il piano di controllo.
- Se questo server serve ad interconnettere reti diverse, anche appartenenti a provider diversi, nasce il problema della responsabilità della sua gestione.
Vantaggi
[modifica | modifica sorgente]- È più flessibile del 6to4, perché consente l'uso di tutti gli indirizzi global unicast.
Portare il supporto a IPv6 ai margini della rete
[modifica | modifica sorgente]Soluzioni basate su NAT
[modifica | modifica sorgente]
L'obiettivo è migrare grandi reti di provider, in modo che le nuvole IPv4 e/o IPv6 al margine della rete possano usare il backbone IPv6 per interoperare. Lo scenario comune è un utente che vuole connettersi a una destinazione IPv4 attraverso la rete IPv6 del provider.
Tutte le opzioni disponibili fanno uso del NAT. L'utilizzo del NAT è un po' controcorrente dato che IPv6 aveva tra gli obiettivi quello di evitare l'utilizzo dei NAT nelle reti a causa dei numerosi problemi portati dai NAT (modifica dei pacchetti in transito, problemi su reti peer-to-peer, ecc.). Tuttavia il fatto che queste soluzioni sono basate su NAT presenta una serie di vantaggi: i NAT sono largamente diffusi nelle reti, se ne conoscono problemi e limitazioni, si conoscono le applicazioni che possono avere dei problemi nel passare attraverso i NAT; così in generale il vantaggio è la grande esperienza accumulata finora.
Principali componenti
[modifica | modifica sorgente]Nelle soluzioni basate su NAT ci sono tre principali componenti:
- Customer-Premises Equipment (CPE): è il router all'edge del cliente subito prima della rete del provider;
- Address Family Transition Router (AFTR): è un IPv6 Tunnel Concentrator, cioè l'apparato alla fine di un tunnel IPv6;
- NAT44/NAT64: è un NAT per la traduzione degli indirizzi IPv4/IPv6 in indirizzi IPv4.
Principali soluzioni basate su NAT
[modifica | modifica sorgente]- NAT64;
- Dual-Stack Lite (DS-Lite): NAT44 + 4-over-6 tunnel;
- Dual-Stack Lite Address+Port (DS-Lite A+P): DS-Lite con intervalli di porte preconfigurati;
- NAT444: CGN + CPE NAT44, ovvero quando un utente domestico, che riceve il servizio dalla compagnia telefonica, inserisce un NAT nella propria rete domestica; ogni pacchetto in uscita dalla rete domestica è sottoposto a due address translation;
- Carrier Grade NAT (CGN): NAT44 su larga scala, ovvero NAT utilizzato dalle compagnie telefoniche per mappare le centinaia di migliaia di indirizzi privati (degli utenti) nei limitati indirizzi pubblici a disposizione.
Per la migrazione di grosse reti orientate a dispositivi mobili si sta scegliendo la soluzione con NAT64.
Per migrare verso IPv6 mantenendo la compatibilità IPv4 ai margini della rete alcuni operatori telefonici stanno pianificando migrazioni massive a DS-Lite poiché è una soluzione abbondantemente sperimentata, ed esistono numerosi dispositivi compatibili già in commercio.
La soluzione A+P non è ancora presa seriamente in considerazione a causa della poca esperienza.
NAT64
[modifica | modifica sorgente]
- L'utente solo IPv6 digita
www.example.comnel browser, ed essendo IPv6 invia una richiesta AAAA al DNS64 del provider. Si supponga chewww.example.comabbia l'indirizzo IPv4 "20.2.2.2". - Il DNS64, in caso non abbia la risoluzione del nome, deve inviare la query ad un DNS superiore, presumibilmente nella rete IPv4.
- Nel caso migliore DNS64 invia la query AAAA al DNS superiore e ottiene una risposta di tipo AAAA (quindi IPv6), che ritrasmette così com'è all'host (è assolutamente lecito inviare in un pacchetto IPv4 una query DNS che richiede la risoluzione di un nome in un indirizzo IPv6).
- Nel caso peggiore il DNS superiore non ha supporto IPv4, quindi risponde con un "Name error"; il DNS64 invia nuovamente la query ma questa volta di tipo A, a seguito della quale riceverà una risposta corretta. Questa risposta verrà convertita in AAAA e ritrasmessa all'host. Nella risposta trasmessa all'host, gli ultimi 32 bit sono uguali a quelli inviati dal DNS superiore nel record di tipo A, mentre gli altri 96 bit completano l'indirizzo IPv6; quindi l'indirizzo finale sarà "64:FF9B::20.2.2.2".
- L'host è ora pronto a instaurare una connessione TCP con
www.example.com. - Entra in gioco il NAT64: converte il pacchetto IPv6 proveniente dall'host in IPv4, e fa l'operazione inversa per i pacchetti provenienti da 20.2.2.2.
Considerazioni
[modifica | modifica sorgente]- In un scenario del genere non c'è tunneling: l'intestazione IPv6 viene solo sostituita con una IPv4 e viceversa.
- L'host solo IPv6 non è consapevole del fatto che l'indirizzo di destinazione è relativo a un indirizzo IPv4.
- Il NAT64 non solo è in grado di tradurre indirizzi IPv6 in indirizzi IPv4, ma in una certa maniera fa credere alla rete che ci sono a disposizione 232 indirizzi IPv6 dato che ogni pacchetto dall'host al NAT64 avrà come indirizzo di destinazione "64:FF9B::20.2.2.2", con il prefisso "64:FF9B/96".
- La rete del provider, quella in cui si trovano il NAT64 e il DNS64, è IPv6 nativa, quindi un host nella rete del provider può contattare direttamente un altro host dotato di supporto IPv6 senza coinvolgere in alcun modo il NAT64.
- "64:FF9B/96" è lo spazio di indirizzamento standardizzato appositamente per questa tecnica di traduzione, assegnato al NAT64, ma l'amministratore di rete potrebbe decidere di cambiarlo a seconda delle necessità. Si noti che l'amministratore di rete deve configurare l'instradamento affinché ogni pacchetto avente tale prefisso vada al NAT64, e deve configurare il NAT64 affinché traduca ogni pacchetto IPv6 avente tale prefisso in IPv4 e lo inoltri nella nuvola IPv4.
Svantaggi
[modifica | modifica sorgente]- La presenza del NAT introduce un problema tipico: l'host dietro il NAT non può essere facilmente raggiunto dall'esterno.
- Succede spesso che quando un DNS non ha la risoluzione di un indirizzo non risponde affatto, invece di inviare un "Name error"; il risultato è un allungamento dei tempi a causa dell'attesa del timeout del DNS64, che alla scadenza del timeout invia una query di tipo A.
- Questa soluzione non funziona se l'utente vuole digitare direttamente l'indirizzo IPv4: l'utente deve sempre specificare il nome della destinazione.
DS-Lite
[modifica | modifica sorgente]
La soluzione Dual-Stack Lite (DS-Lite) consiste nella semplificazione dei CPE spostando le funzionalità di NAT e DHCP ai margini della rete del provider, quindi in un apparato che funge da AFTR e da CGN-NAT44.
- Il server DHCP del provider assegna un indirizzo IPv6, univoco all'interno della rete del provider, ad ogni host di ogni CPE.
- Quando l'utente deve spedire pacchetti IPv4 è necessaria un'operazione di tunneling, in modo da incapsulare pacchetti IPv4 in pacchetti IPv6 dato che la rete del provider è solo IPv6. Allora, quando un CPE riceve un pacchetto IPv4 lo deve far passare in un tunnel in un pacchetto IPv6 per poterlo spedire all'AFTR oltre il quale c'è la nuvola IPv4; quindi lo scenario è costituito da tante operazioni di tunneling sulla rete IPv6 del provider tra l'AFTR e uno dei numerosi CPE degli utenti. In particolare, il pacchetto tra CPE e AFTR avrà come indirizzo sorgente quello dell'AFTR, e come indirizzo di destinazione quello della destinazione nella rete IPv4.
- L'AFTR, dopo aver eliminato l'intestazione IPv6, lo invia al NAT44 che sostituisce l'indirizzo sorgente IPv4 (privato) con l'indirizzo IPv4 a cui il NAT riceverà i pacchetti associati a questo flusso.
Il vantaggio maggiore di DS-Lite è quello di ridurre notevolmente il numero di indirizzi pubblici del provider.
Possono esserci indirizzi IPv4 duplicati nella rete del provider? No, perché il NAT44 traduce direttamente gli indirizzi IPv4 degli host negli indirizzi IPv4 pubblici disponibili. Se ci fossero indirizzi IPv4 privati duplicati il NAT avrebbe problemi di ambiguità.
Svantaggi
[modifica | modifica sorgente]- Un host IPv4 non può contattare una destinazione IPv6 → le destinazioni IPv6 sono raggiungibili solo da host IPv6. Invece, un host IPv6 può spedire e ricevere pacchetti da nodi IPv6 senza passare attraverso l'AFTR del provider.
- Alcuni tipi di applicazioni non sono in grado di funzionare in una situazione del genere: il fatto che il NAT non sia gestibile dall'utente, dato che non si trova più sul CPE, rende impossibile effettuare operazioni comuni come l'apertura/chiusura delle porte necessarie a specifiche applicazioni.
DS-Lite A+P
[modifica | modifica sorgente]
La soluzione Dual-Stack Lite Address+Port (DS-Lite A+P) consiste nell'avere ancora una rete del provider solo IPv6, ma il NAT viene spostato sul CPE in modo che l'utente possa configurarlo in base alle proprie esigenze.
Come in DS-Lite, un pacchetto IPv4 in uscita dal CPE viene ancora fatto passare in un tunnel poiché la rete del provider è solo IPv6.
Il fatto che il NAT su ogni CPE richieda un indirizzo IPv4 pubblico viene risolto permettendo la duplicazione di indirizzi IPv4 pubblici, e i CPE vengono distinti in base alla porta. Infatti ogni CPE utilizza un determinato intervallo di porte, e l'AFTR, che conosce l'intervallo di porte utilizzato da ogni CPE, riesce a distinguere i flussi da e verso uno specifico CPE nonostante ci siano diversi CPE aventi lo stesso indirizzo IPv4 pubblico.
Questa soluzione è simile a quella con DS-Lite, ma lo spazio di indirizzi IPv4 privati è più sotto il controllo dell'utente finale, perché dato che il NAT è sul CPE dell'utente l'utente può configurarlo, anche se con alcune limitazioni: non può aprire e usare porte che non sono nel proprio intervallo. Questo metodo permette di risparmiare indirizzi IPv4 (ma comunque meno rispetto a DS-Lite).
Questa soluzione in Italia è sostanzialmente illegale perché, siccome il numero di porta non viene memorizzato, in caso di attacco non si riuscirebbe a risalire all'attaccante.
Trasportare il traffico IPv6 nella rete centrale
[modifica | modifica sorgente]L'obiettivo principale è avere nella rete globale traffico IPv6 senza stravolgere la rete esistente da più di 20 anni che attualmente funziona bene. Non sarebbe possibile sostenere costi di migrazione umani e tecnologici a livello mondiale per cambiare radicalmente la rete IPv4 esistente per renderla IPv6.
6PE
[modifica | modifica sorgente]L'obiettivo della soluzione 6 Provider Edge (6PE) è connettere delle nuvole IPv6 tra loro attraverso un backbone MPLS. 6PE richiede che la rete dell'operatore funzioni con MPLS. In questo scenario il margine del provider è rappresentato dai primi router che incontrano i CPE degli utenti.
Idea
[modifica | modifica sorgente]- Mantenere invariato il core della rete (senza escludere la possibilità di future modifiche).
- Aggiungere il supporto a IPv6 al margine della rete del provider.
- Distribuire informazioni di routing IPv6 in MPLS/BGP, come nelle VPN:
 Tecnologie e servizi di rete/VPN#Livello 3: BGP.
Tecnologie e servizi di rete/VPN#Livello 3: BGP.
Requisiti
[modifica | modifica sorgente]
Il requisito fondamentale è avere una rete centrale MPLS.
Nella figura:
- la rete centrale MPLS è quella costituita da PE-1, P-1, P-2, PE-2;
- i due apparati laterali, PE-1 e PE-2, sono parzialmente immersi nella rete MPLS;
- si può pensare ai canali tra CE e PE come dei canali che forniscono collegamento ADSL all'utente domestico.
6PE è pensato per prendere una rete centrale pienamente funzionante, in grado di trasportare pacchetti IPv4 con MPLS, e aggiungere il supporto IPv6 solo agli edge router del provider (PE). Infatti, una volta che un pacchetto viene incapsulato in un pacchetto MPLS, gli apparati intermedi non si interesseranno più al tipo di pacchetto contenuto, ma saranno solo interessati alla etichetta che permette loro di distinguere l'LSP nel quale instradarlo.
Infatti, sui PE è richiesto un ulteriore aggiornamento al fine di aggiungere il supporto MG-BGP, protocollo che permette di trasportare e comunicare sia rotte IPv4 sia rotte IPv6.
Quindi il grosso vantaggio di questa soluzione consiste nel richiedere l'aggiornamento solo dei PE e non di tutti i router intermedi: in fin dei conti, un'operazione che il provider può gestire senza elevati costi.
Come vengono annunciate le reti IPv6
[modifica | modifica sorgente]- CE-3 annuncia che può raggiungere la rete IPv6 "2001:3::/64".
- Questa informazione viene ricevuta anche da PE-2.
- PE-2 invia questa informazione a tutti i PE nella rete, dicendo che può raggiungere "2001:3::/64" attraverso il next hop "FFFF:20.2.2.2", nonostante la sua interfaccia sia IPv4 (questo perché se è data una rotta IPv6 deve essere dato un next hop IPv6).
- PE-1 riceve questa informazione.
- PE-1 invia l'informazione ricevuta a tutti i router ad esso collegati, quindi anche ai CE domestici, dicendo che può raggiungere la rete "2001:3::/64".
- Se non esiste ancora un percorso MPLS tra PE-1 e l'indirizzo "20.2.2.2", vengono usati i classici meccanismi MPLS (quindi il protocollo di segnalazione LDPv4) per instaurare questo percorso.
Come viene instradato il traffico IPv6
[modifica | modifica sorgente]
Per instradare un pacchetto IPv6 vengono utilizzate due etichette:
| etichetta esterna LDP/IGPv4 verso PE-2 | etichetta interna MP-BGP verso CE-3 | pacchetto IPv6 verso la destinazione IPv6 |
- etichetta MP-BGP (interna): identifica il CE di destinazione a cui il PE di destinazione deve inviare il pacchetto;
- etichetta LDP/IGPv4 (esterna): identifica l'LSP tra i due PE nella rete MPLS.
Si supponga che un host nella rete "2001:1::/64" voglia inviare un pacchetto a un host nella rete "2001:3::/64":
- il pacchetto arriva a CE-1;
- CE-1 sa che la rete "2001:3::1/64" esiste e invia il pacchetto verso PE-1;
- PE-1 mette due etichette davanti al pacchetto: l'etichetta interna e l'etichetta esterna;
- PE-1 invia il pacchetto a P-1, che lo invia a P-2;
- P-2, che è il penultimo hop, rimuove l'etichetta esterna dal pacchetto (penultimate label popping) e lo invia a PE-2;
- PE-2 rimuove l'etichetta interna e invia il pacchetto a CE-3;
- CE-3 inoltra il pacchetto alla destinazione nella rete "2001:3::/64".
Considerazioni
[modifica | modifica sorgente]- I router PE devono essere dual stack e devono supportare MP-BGP, mentre i router intermedi non hanno bisogno di alcuna modifica.
- Questa soluzione fornisce un servizio IPv6 nativo ai clienti senza cambiare la rete centrale MPLS IPv4 (richiede costi e rischi operativi minimi).
- Questa soluzione scala fino a quando ci sono poche nuvole IPv6 da distribuire.
Problematiche di sicurezza
[modifica | modifica sorgente]Si ha poca esperienza con i problemi di sicurezza perché IPv6 non è ancora molto usato → IPv6 potrebbe ancora avere delle falle di sicurezza non scoperte che potrebbero essere sfruttate da malintenzionati. Inoltre, durante la fase di migrazione gli host hanno bisogno di aprire due porte in parallelo, una per IPv4 e un'altra per IPv6 → devono essere protette due porte da attacchi dall'esterno.
- Attacchi DDoS con SYN flooding
L'interfaccia di un host può avere più indirizzi IPv6 → può generare più richieste SYN TCP, ognuna con un diverso indirizzo sorgente, a un server al fine di saturarne la memoria facendo aprire ad esso diverse connessioni TCP non chiuse.
- Messaggi Router Advertisement falsi
Un host potrebbe iniziare a mandare dei messaggi "Router Advertisement" annunciando dei prefissi falsi → gli altri host nel link inizieranno a inviare pacchetti con dei prefissi sbagliati negli indirizzi sorgente.